Today, we tell you the story of how we solved our Magento core_url issues, which might be very familiar and similar to you, since you’ve landed here.
Today, we tell you the story of how we solved our Magento core_url issues, which might be very familiar and similar to you, since you’ve landed here.
If you have been working with Magento for long enough, chances are that sooner than later you’d have learnt that there are a two fundamental steps to follow if you are having issues:
- It’s always the cache! Whenever something doesn’t work, clear the cache, and I mean, all of them! And the problem will (or not) go away, it’s like rebooting in Windows!
- If that doesn’t work, run a full reindex, and repeat the above step 🙂
That’s why it’s is not only recommended, but also it’s very common to run reindexes daily, and most likely even more often, whenever we want to immediately reflect some changes in the front-end, such a new stock, new products, or new category-products assignments.
Reindexing often shouldn’t be a problem for small stores, but the more products you have, the more probable is that reindexing is going to cause you trouble due the long time that it takes, the amount of resources that it needs, and so on, as well as the fact that they need to run overnight to avoid slowing down your website dramatically.
Whenever a full site reindex is taking a long time, 99% of the cases “catalog_url” reindex is the one spending most of the time, specially if you have a large catalog of products and or if you have a multi-store setup.
Unfortunately or otherwise, that was our case at our bikes shop. We had several thousand products and, even though a big part of them are currently disabled, the reindex was taking far too long, and the table core_url_rewrite was growing exponentially, causing other problems such as slowing down the backup process, or preventing the sitemap generation from running, due big SQL queries taking far too long to run.
Like in most existing online stores, all of these could have been easily avoided if it had been addressed properly from the beginning, but you know… could’ve, would’ve, should’ve… but didn’t!
So, there we were, with a core_url_rewrite table with over 210k rows, and expanding beyond maintainability. We had only two chances:
- Upgrade the servers and ignore/delay the problem until we reach to this same stage in a couple of months time.
- Tackle the problem and invest the time needed to find out what’s going on, and sort it out properly
We love challenges, and the first option wasn’t even considered, as it wasn’t a solution really, so we got our hands on it and started to look into the possible causes.
We identified two major problems looking into core_url_rewrite table:
- There were several thousand rows with URLs about products that were disabled or not visible individually. We had already installed Dn’D module that skips the reindex of disabled and not visible products, speeding up the reindex by keeping them out of the table, but there “leftovers” from the past, before the module was installed. If you don’t have Dn’D Patch Index Url module installed, please take a few minutes and install it right know, it’s a must have for any Magento store.
- We noticed a very interesting issue: Every time we run a catalog_url reindex, the number of rows of the core_url_rewrite table was increased, even when there were no recent changes on the catalog. So, basically, the table was growing and growing each time without any obvious reason.
In order to address the first problem, we built two queries to identify the rows corresponding to:
Disabled products:
SELECT count(*) FROM core_url_rewrite WHERE product_id IN (SELECT entity_id FROM catalog_product_entity_int WHERE attribute_id = (SELECT attribute_id FROM eav_attribute WHERE attribute_code ='status') AND VALUE = 2 AND entity_type_id = 4);
Roughly 2k rows.
Then, we did the same to identify the products with Visibility set to Not Visible Individually:
SELECT count(*) FROM core_url_rewrite WHERE product_id IN (SELECT entity_id FROM catalog_product_entity_int WHERE attribute_id = (SELECT attribute_id FROM eav_attribute WHERE attribute_code ='visibility') AND VALUE = 1 AND entity_type_id = 4);
Nearly 8k rows.
Since the above queries return rows that correspond to products not being displayed on the front-end (because they are disabled of not visible in the catalogue), they can safely be removed without any impact on the front-end/SEO.
The infinite growing “duplicated” redirects on core_url_rewrite
This is a very interesting issue which is widely known among Magento developers. There is a good thread on StackExchange discussing it, where you can find responses of all kinds. In the above link, people have done a great job analysing the problem, and some even propose (partial) decent solutions to it, but given the complexity, many people have also given up to find a fix. In fact, Alan Storm himself, one of the most popular Magento developers advises so, and his answer is the second most voted, which by the way is pretty disappointing to say the least.
In our case, it was unacceptable to leave it as it was, because we were aware of the issue, and we had been delaying it for a while. Eventually, it was causing us serious issues, and it was having a pretty bad impact in the overall performance of our store, so it had to be addressed.
As we mentioned previously, every time we reindex the “catalog_url”, the amount of rows on the table core_url_rewrite was increasing, and we were trying to figure out why. It seems that the problem is caused when there are two or more products/categories with the same URL key. During the reindex, Magento checks whether the url key is unique, if it’s not, it appends the entity_id of the product to the URL to make it unique. The problem is that next time the reindex runs, it will do the same process, but the new URL (url_key + entity_id) already exists, so Magento tries increasing the numeric part of the url key (product’s entity id) until it finds a unused URL, and it keeps creating crazy redirects on each run.
One way to avoid/overcame this issue is making sure that the url_keys of the products are unique. We tested that approach in first place, running a query that modified the url_key (attribute of the product) of each product that has duplicates, appending the entity_id followed by a dash. Ie. product with id 123 and url_key “my_product” would become “my_product-123”. This way when the reindex runs, all URLs would be unique, and Magento wouldn’t have to do “his thing”. However, this would be messing up with existing URL redirects in core_rewrite_url and potentially would lead to broken links. Also, it wouldn’t fully resolve the issue, as nothing would be preventing new products from being created/imported with duplicated URL keys in the future, so we had to find a better solution.
Since many people had been investigating and debugging this problem, we decided to have a look at the proposed solutions on StackExchange and tested some of them. The solution proposed by @Simon was the one that made more sense for us, and it seemed to do the job. After applying the code changes, reindexing wouldn’t increase the number of rows of the table. However, the proposed solution was overriding the core, which is something we never do unless it’s something unavoidable. It’s a nice solution, wrapped as an “unofficial Magento patch”, but we didn’t want to take the risk of having future upgrade/patching issues. So, we decided to create a new Magento extension, which would override the model Mage/Catalog/Model/Url.php, and we put Simon’s fix there, leaving the core untouched. It all seemed to work fine, and the table core_url_rewrite stabilised so the first step was done, now it was time for the tricky part, the remaining “leftovers”.
We had 210k rows (well, actually 200k after the previous clean-up of disabled/not visible products) on the core_url_rewrite table, but as we mentioned previously, we have only a couple of thousand products enabled in our catalog, so presumably many rows were not really “needed”, and most likely the “oversize” of the table was related to the infinite rewrites/redirects.
Looking at the latest entries of the core_url_rewrite, there was a clear pattern on the redirects:
| Product_id | Request_path | Target Path |
| 1234 | product-url-key-1234.html | product-url-key-1235.html |
| 12 | product-url-key-13.html | product-url-key-14.html |
Both, request_path and target_path look the same except for the number prepended to the url_key. So, we came up with this query to identify all the redirects:
SELECT count(*) FROM core_url_rewrite WHERE product_id IS NOT NULL AND LEFT(request_path, length(`request_path`) - 5 - length(product_id)) = LEFT(target_path, length(`target_path`) - 5 - length(product_id)) AND is_system = 0
Result: 195k rows!!! Unbelievable, we thought those rewrites were bad, but we didn’t expect that they would be THAT BAD!
Right, so we wanted to get rid of all that “junk” redirects, but we couldn’t just delete them. Well, technically we could, but that could have a very bad SEO impact, it would generate many 404 errors for products already indexed in the search engines, and there would be existing links to the products in newsletters, social media, etc. So we needed an strategy to fix it.
After a lot of testing and back and forth, eventually we did the following:
- Create a table core_url_rewrite_tmp which contains only the redirects (can be done with one query, using create table as select):
SELECT category_id, product_id, store_id, request_path, target_path FROM core_url_rewrite WHERE product_id IS NOT NULL AND LEFT(request_path, length(`request_path`) - 5 - length(product_id)) = LEFT(target_path, length(`target_path`) - 5 - length(product_id));
- Override Mage_Cms_IndexController::noRouteAction to capture 404 events
- Then, whenever a 404 happens, check if the request matches the below pattern:
'/\\/(.*)-\\d+.html/'- If it doesn’t, let Magento handle the 404 normally
- If it does, query our new table and search for matches on the current store, fetching the product_id or category_id.
- If there are no matches, let Magento handle the 404 normally
- If there are matches, redirect the user to the corresponding product/category (301 – permanent redirect) URL
After having this kind of fallback mechanism, the redirect entries can be removed from the core_url_rewrite table.
Then, the core_url_rewrite table is completely clean and light, which, being one of the critical and most used and joined tables of Magento, has a shocking impact in the overall performance of the site, not to mention the massive speed increase on heavy tasks such as sitemap generation, core url reindex, and so on.
In our case, as a result of this whole clean-up, the core_url_rewrite now has 5k rows. We still have to keep the “core_url_rewrite_tmp”, but that table is queried in very rare occasions (vs the frequency of core_url_rewrite), when an “old URL” is requested.
Last but not least, since we are sending all the requests to the right destination with a 301 redirect, within a couple of months, all the search engines would have updated their indexes and the table can be “safely” removed.
Note that there might still be old links in emails, social media, etc., but the fallback can then be amended to redirect users either to the catalog search (searching for the requested URI), or it can do a best-match on the core_url_rewrite and redirect the user to the closest match. This won’t be 100% accurate as the products with the duplicated URL keys would have similar url keys/names. However, on this fast moving age, after 6 months those links are highly unlikely to be hit.
We deleted our table after 3 months, and two weeks later we haven’t found any related 404 in our reports.
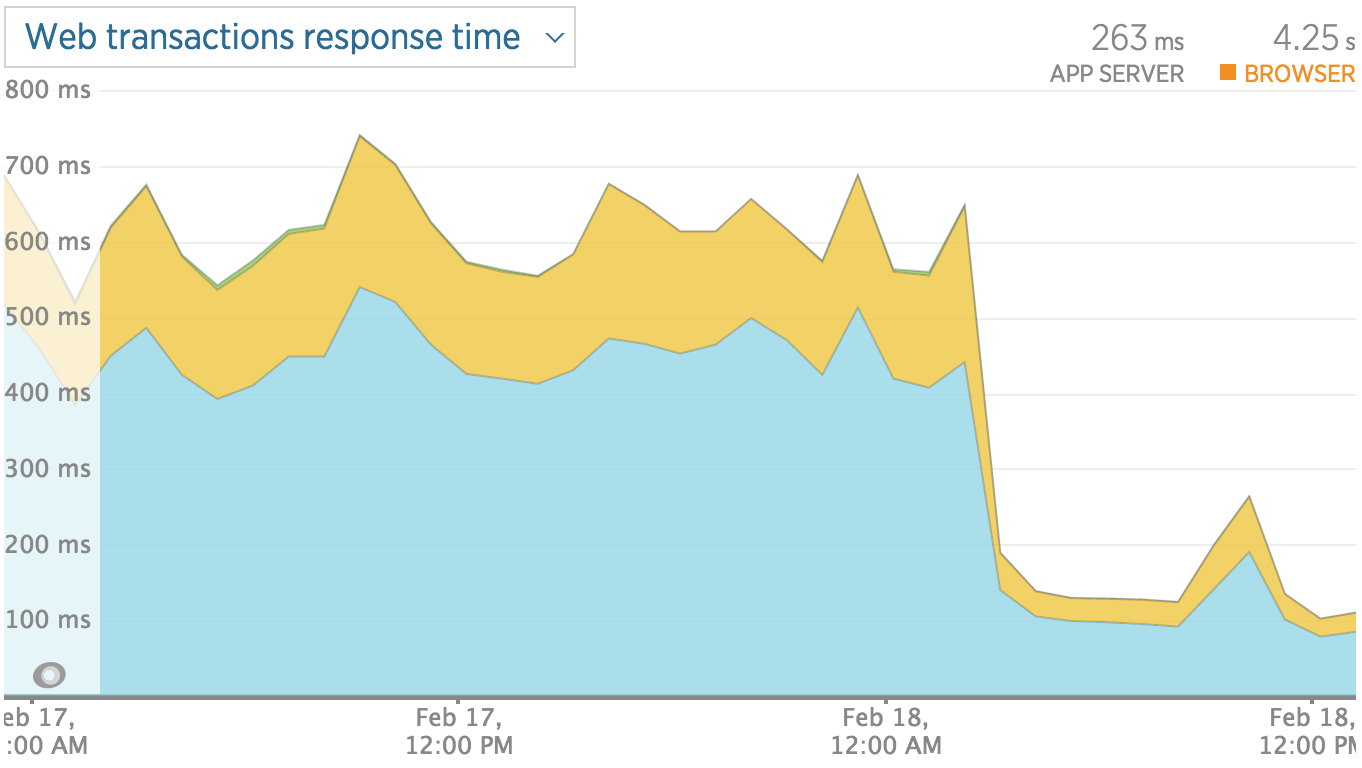
Finally, our zipped database (excluding orders) dropped from 80Mb to 5Mb, all our sitemap generation and reindex issues were resolved, and our website overall speed/performance improved noticeably, so we couldn’t be happier 🙂
 Speeding up Magento is the headache of many shop owners, which usually contact us frustrated after seeing how their page loads are way above the market average, causing a really high bounce rate.
Speeding up Magento is the headache of many shop owners, which usually contact us frustrated after seeing how their page loads are way above the market average, causing a really high bounce rate.